
Resilience Hub

Every organization knows resilience is important. But the real question is: how do you build and sustain it? The common answer is to hire an internal department. On paper, that makes sense — until you look at the costs, the cultural realities, and the long-term cycle that organizations fall into. The smarter approach? Resilience-as-a-Service (RaaS) or its many other names (Business-Continuity-as-a-Service (BCaaS), Disaster-Recovery-as-a-Service (DRaas), etc.). The True Cost of an Internal Resilience Department Standing up a department means building a mini-organization inside your organization. Here’s what that typically looks like: Director of Business Resilience: $150K–$200K BC/DR Manager: $110K–$150K Analyst/Coordinator (x2): $70K–$100K each Training, Tools, and Software: $50K–$100K annually Total Yearly Spend: $500K–$650K+ That’s half a million dollars every year and that’s before you account for turnover, retraining, and months lost while new hires climb the learning curve. The Reality of Internal Departments: The “Resilience Cycle” Here’s the part no one likes to say out loud: The Build-Up (Years 1–2): Leadership approves funding, hires staff, and resilience gets the spotlight. The Plateau (Years 3–4): Once the program “looks complete,” executives start seeing the department as a cost center. Budgets shrink, headcount is cut, and resilience gets pushed to the sidelines. The Hollowing (Year 4+): The department often becomes a one-person office with little budget and less authority. That person does their best, but resilience isn’t truly organizational, it’s paperwork. The Disaster Wake-Up: A disruption hits. Leadership panics, realizes resilience matters again, and often fires the last holdover , bringing in someone new who wants to do things “their way.” The Reset: The cycle starts over. Each reset means knowledge loss, cultural whiplash, and ultimately less resilience than before. It’s a vicious cycle and one that wastes time, money, and credibility. Why Resilience-as-a-Service Breaks the Cycle RaaS flips the model by treating resilience like a service, not a siloed department. Advantages Cost Efficiency: RaaS typically runs at 25–50% of the cost (depending on what your organization needs) of an internal department. You pay for outcomes, not headcount. Cross-Industry Expertise: RaaS teams bring decades of experience across multiple industries and regulatory environments. Regulator & Auditor Fluency: Smaller firms have been in the room with regulators. They know the playbook and what holds up under scrutiny. Faster Ramp-Up: You’re operational in weeks, not years. Scalable & Flexible: Need BIAs today, crisis simulations tomorrow, and vendor risk assessments next quarter? RaaS flexes with you. Continuity: With RaaS, you’re not subject to staff churn or leadership fads. The expertise stays consistent. Disadvantages of RaaS (And Why They’re Manageable) Not “Always On”: Consultants aren’t sitting in your office. But the right partner provides on-call support and structured handoffs. Knowledge Retention: If you don’t absorb lessons, you risk dependency. Strong RaaS providers bake in training and documentation to prevent this. Smaller Firms are Better Let’s be blunt: Big 4 firms rarely bring hands-on resilience experience. You’ll get frameworks and slide decks, not operational depth. Smaller firms are practitioner-led. They’ve actually managed incidents, dealt with regulators, and built programs in the trenches. Better Fit. Smaller firms adapt resilience to your culture. Big 4 tend to impose their model, which is usually worse than hot garbage. The Bottom Line – Cause Stone Cold Said So Resilience isn’t about building an empire, it’s about ensuring your organization can survive disruption. Internal departments often follow a predictable cycle: big start, slow decline, painful reset. That cycle costs more, delivers less, and leaves organizations exposed. Resilience-as-a-Service breaks the cycle. It gives you cost-efficient, regulator-ready expertise that scales as you need it, without the bloated budgets and political churn of an internal department. When the next disruption hits, the question won’t be “why didn’t we invest more internally?” It will be “why didn’t we choose resilience a service in the first place?”
May resilience professionals/consultants seem to recycle the same tired advice: “To build resilience, you need to change the culture.” That sounds inspiring, but let’s be real, it’s not how organizations actually work. Culture isn’t Play-Doh you can shape with a half-day workshop. It’s concrete that’s been setting for decades. And even if you manage to chip away at it, it’ll harden back the moment leadership turns over or priorities shift. The smarter approach? Fit resilience to the culture that already exists. Why Culture Doesn’t Change (At Least, Not How You Think) History wins. Culture is baked in through leadership styles, incentives, and unwritten rules that outlast org charts and rebrands. Short bursts fade. You can get a temporary rally when executives preach resilience, but the default behaviors come roaring back once attention drifts. Resistance is human. Employees don’t want to reinvent how they work just to satisfy another initiative. If resilience feels foreign, it won’t stick. A Real-World Case: Jack Henry I lived this firsthand. At Jack Henry, regulators had put the company under an agreement that made resilience a top priority. I had nearly three years to “change the culture.” And for a while, it worked. Executives were engaged, resilience was in every conversation, and entire teams were built around it. But the moment the agreement ended, resilience started to slide straight to the sidelines. The culture didn’t hold; it simply reverted to what it had been before. Today, most of the staff we had in place then aren’t even there anymore and I don't think they have been replaced. The “cultural shift” didn’t stick because it was never really a shift. It was a compliance response. Fitting Resilience to Culture: How It Actually Works 1. Hierarchical, Command-and-Control Cultures Think: financial institutions, airlines, government agencies. Don’t fight it. Decision-making is top-down, so make resilience executive-driven. How it works: Instead of 15-page departmental BIAs, run an Executive BIA to map which functions leadership sees as critical. Then design playbooks that let staff execute orders quickly instead of debating priorities in a crisis. 2. Entrepreneurial, Decentralized Cultures Think: tech startups, consulting firms, creative agencies. Don’t add red tape. These organizations thrive on flexibility, not process-heavy binders. How it works: Push resilience into micro playbooks—two-page guides or quick decision trees—so managers can act without waiting for HQ approval. Pair it with tools they already use (Slack, Teams, or even shared docs) instead of forcing new systems. 3. Process-Heavy, Compliance-Driven Cultures Think: healthcare systems, utilities, manufacturers. Don’t reinvent the wheel. These teams live and breathe checklists, audits, and standard procedures. How it works: Bake resilience into the compliance process. Add risk and continuity checkpoints into existing audits instead of inventing parallel ones. Train staff using the same cadence as regulatory refreshers—make resilience another box they know how to check. The Takeaway Instead of asking: “How do we change culture to fit resilience?” Ask: “How do we design resilience so it thrives inside this culture without constant enforcement?” Because resilience that depends on a cultural shift is fragile. Resilience that plugs into the way people already think and work? That lasts.

For the past year, I’ve been busy building applications in Node.js, React, and other modern frameworks. But my first love has always been Power Apps. The ease of building, the ability to tie multiple apps together, and the power to integrate directly with the tools an organization already uses means you’re no longer stuck doing things the way a company like Everbridge thinks resilience should be done. Instead, you can build the program you actually want and need, one that works more efficiently, fits your organization perfectly, and costs a fraction of what you’re probably spending now. For years, Everbridge has been the brand name people throw around when they talk about mass notification. It’s been the “safe” choice, the one that looks good on a board slide and makes executives feel like they’ve bought peace of mind. But in 2025, that old model doesn’t just feel outdated. It’s overpriced, overly complex, and tied to a vendor you’ll never truly own. The reality? Most organizations can build 90% or more of what Everbridge offers inside Microsoft Power Apps , using the tools they already have without paying a six-figure annual bill. And with the right approach, you can go beyond just notifications, creating a fully integrated resilience platform that actually improves how you respond when things go wrong. The Cost Problem Everbridge isn’t cheap. There’s the licensing fee, which is high enough on its own. Then there’s the setup. Then the customization. Then the training. And heaven help you if you want the system to work the way your organization works because that’s when the real costs kick in. I’ve seen organizations hire Everbridge’s own developers just to make the product usable for their needs. With Power Apps, you already have the foundation if your organization runs Microsoft 365. There are no per-alert or per-user charges. The free connectors tie into Outlook, Teams, SharePoint, and more without forcing you into premium licensing for every employee. You build it once, you own it forever. That’s a huge shift from the “keep paying or lose it all” model that drives most legacy notification platforms. Control and Customization Here’s the other issue with Everbridge: out of the box, it’s not great. The interface is clunky. The workflows are buried under layers of clicks. If you want to tailor it, you either accept its limitations or you pull out the checkbook. Power Apps flips that model on its head. You can design the interface, the workflows, and the automation to fit your exact processes. Need notifications to trigger from an incident record in SharePoint? Done. Want them to integrate directly with Teams channels? Easy. Need an escalation that emails executives, pings operations in Teams, and sends a push notification to field staff simultaneously? You can build it without a single upsell. The Personal Data Problem Most mass notification tools rely heavily on collecting personal cell phone numbers. That’s a constant headache. Employees don’t always want to give them out. Numbers change. There are privacy and legal issues in some regions. And if your database gets compromised, you’ve just exposed personal information you didn’t even need. With Power Apps, there’s no need to ask for personal contact data. Employees log in with their work email, download the app, and get push notifications instantly. It works globally without SMS fees, carrier delays, or compliance nightmares. Where Everbridge Still Wins To be fair, Everbridge still has the edge in a few very specific areas: carrier-level SMS/voice redundancy, public safety integration like IPAWS, massive-scale geo-targeting for millions of recipients, and automated compliance with international SMS laws. If you’re a national public safety agency or you need to reach millions of people in minutes, Everbridge still has the infrastructure to support that. But here’s the key: most private-sector organizations don’t need any of that. And for everyone else, those “advantages” aren’t worth the price tag. Beyond Notifications: Building Your Entire Resilience Program This is where Power Apps becomes a game-changer. Your notification system doesn’t have to be a standalone tool. It can be part of an entire resilience ecosystem built inside Power Apps. Imagine this: A mass notification app tied directly into your crisis management dashboard. Your BIA and risk assessment tools connected so you know exactly what functions are impacted and how to prioritize. Resource and vendor management apps ready to mobilize support instantly. Coordination tools that keep executives, crisis teams, and operational staff on the same page, in real time. When those apps talk to each other, you’re not just sending alerts, you’re managing the entire disruption from one environment your people already use every day. That’s something no standalone notification vendor can deliver without expensive integrations and ongoing fees. How PAI Consulting Can Help At PAI Consulting , we build mass notification systems in Power Apps that your organization will actually own. You deal with us once (we design, build, and deploy the system) and then it’s yours forever. No annual vendor ransom. No surprise costs. No per-user licensing fees. And if you want to go beyond alerts, we can help you design your entire resilience program in Power Apps. That means every app in your response toolkit can be tied together, so you’re not just reacting, you’re responding faster, smarter, and more effectively than you ever could with an off-the-shelf vendor product. Everbridge might still work for a handful of organizations. But for everyone else, 2025 is the year to start owning your tools, control your processes, and stop paying for complexity you don’t need.

I didn’t get into resilience because I loved binders or dreamed of sitting in planning meetings. I got into it because my aunt and uncle died in a car wreck—one that could’ve been prevented if someone, somewhere, had put the right mitigation in place. That loss stayed with me. I decided to go back and get a degree in Emergency Management, thinking I’d be out there preventing the next one. If nothing else, I now have a B.A. and a B.S., meaning, I can be a bad-ass bull-sh***er. Too bad Emergency Management pays in peanuts and PowerPoints. So, I pivoted into business continuity, disaster recovery, crisis management. The private sector actually funds this stuff. But what I found was something no one likes to admit: There’s a massive disconnect between what we plan for and what we actually respond to. The Planning Problem Most continuity plans are built around big, flashy disruptions. Floods. Ransomware. Civil unrest. The kind of events that justify the budget and keep executives nodding. But here’s the thing: they’re aimed at the wrong bullseye. Most Business Continuity plans assume you're going to lose a process. Most Disaster Recovery plans assume you're going to lose a system. In reality? You’ll probably still have the process, but no one’s touching it because priorities just changed. You’ll probably still have the system, but it’s slow, throwing errors, or missing the one integration that people actually use. We’ve treated disruption like it’s binary, on or off. But real-world failure is rarely that clean. Systems degrade. Apps bug out. Vendors ghost. Staff get confused. And that “critical” process everyone flagged in the BIA? Turns out it’s not so critical when the actual pressure hits. Back before I worked in resilience, if a tool went down, we just shifted to something else or just used the time to catch our breath. No one called it a disruption. It was just life. But now, with systems stacked on top of systems and “digital transformation” as the buzzword du jour, those little breakdowns ripple fast. And most organizations are still planning like it’s 2010. The Triangle That Actually Works Here’s how I’ve come to see it: Crisis Management sits at the top —the brain making decisions. Business Continuity and Disaster Recovery are the base —feeding it the facts. BC knows what processes are down or degrading. DR knows what tech is impacted or glitching. CM uses both to decide what to do next. That triangle is simple. But in practice, most organizations mess it up. BC and DR get built in silos. CM only gets looped in once people start yelling. And everyone’s working off plans that were written for some dramatic, worst-case scenario, not the kind of middle-tier chaos that actually shows up on a Tuesday. So the decision-making gets clunky. Information doesn’t flow. And the people in charge are left guessing what’s real and what’s noise. Enter: Realistic Resilience This is exactly why we built Realistic Resilience —to stop pretending that glossy documentation equals readiness. We don’t start with documentation. We start with behavior. We ask: How do people actually respond when things go wrong? Who makes the real decisions? What doesn’t get escalated—and why? Then we build systems that: Start with executive-level BIAs because when it hits the fan, the top decides what lives and what dies. Focus on real-time decision support , not just post-mortem audits. Use tools teams already live in ( Power Apps, Teams, SharePoint ) so the plan lives inside the workflow, not buried in a PDF. An additional benefit of building it this way is you own it, not a third party. You can design and update whenever you need to. Acknowledge that not every outage is worth activating the whole protocol and that sometimes doing less is the right response. We also plan for the stuff that doesn’t feel like a big deal, until it is. Because most disruptions don’t start as crises. They start as someone saying, “Hey, is anyone else having trouble logging in?” Final Thought If your resilience program still treats disruptions like binary events, process gone or system down, it’s already missing the point. Real resilience isn’t about reacting to massive, rare events. It’s about navigating the messy, fragmented, uncomfortable middle. It’s about helping leaders make better decisions with better context… fast. That’s what Realistic Resilience is built for. Because response should feel like instinct, not like flipping to page 47.

There’s someone in my industry—won’t name names—who’s built a reputation on other people’s ideas. Not borrowing. Not being inspired. Stealing. Copy-paste. Slight reword. Slap their name on it. Present it at a conference like they came up with it on a meditation retreat. And the worst part? They keep landing clients. That’s the world we live in, where the people doing the work are overlooked, and the people talking about it (loudly) are labeled “thought leaders.” Performance Over Practice I’ve lost count of how many people I’ve seen on stage or in webinars saying impressive things, but I highly doubt many of them have managed a 3AM crisis response in the real world. You know the type: Speaks well, but never implements. Uses vague, sweeping language instead of actual frameworks. Spends more time networking than problem-solving. Their real skill isn’t resilience—it’s salesmanship. They’ve got the gift of gab, a well-lit Zoom setup, and a LinkedIn bio that makes them sound like they invented the concept of continuity planning. These are the people who get stage time at DRJ, DRI, Continuity Insights, and everywhere else. They win clients not because of what they build, but because of how they pitch. Meanwhile, Here’s Me I’m not a great public speaker. I don’t enjoy being in front of an audience. I’m not a great salesman either, but because I actually care whether the client is getting what they need. I’ve lost money on gigs because I put the client’s needs ahead of my own margin. I’ve turned down projects that weren’t ready. I’ve spent more hours than I billed because getting it right mattered more than getting paid. Heck, I've probably given away access to our BR Navigator and Scenario TTX tools more than I've had users pay for it. That’s not glamorous. It’s not scalable. And it definitely doesn’t earn you applause at a conference. But it’s the truth. And over time, that truth taught me something the “experts” never talk about: Most of What I Was Taught About Resilience… Doesn’t Work I’ve built resilience programs from the ground up. I’ve led assessments, exercises, and real-world responses. And what I’ve learned the hard way, is that most of what we push in this field is designed for compliance, not capability. Here’s what I had to unlearn (and am still unlearning - is that even a word?): Handing off templates = engagement? In my first resilience position, I was trained that if I gave departments clear templates, they’d take ownership. They didn’t. They avoided them, or rushed them with vague answers. Lesson: People outside of resilience don't care about it and don't really know what you are trying to find out. Conduct interviews when doing planning, do the typing, and let the participant(s) just talk. They will be able to ask questions and provide you exactly what you are looking for. Once trained = always ready? I thought a strong kickoff or awareness campaign would stick. People forgot everything the moment stress hit. Lesson: If it’s not baked into their workflow, it’s gone. Executives are dying to know how resilient they are? I thought showing risk, gaps, and progress would trigger buy-in. I got ten seconds of attention, if I was lucky. A council I met with quarterly would routinely show the executives looking at their phones or a secondary monitor, just wishing the meeting was over so they could get back to more important things. Lesson: Tie resilience to revenue, liability, or headlines. Otherwise, it’s background noise. Everyone values resilience? I thought once they “got it,” they’d care. They didn’t. Until something went wrong. Lesson: Build your program to work despite apathy. Introduce new methods that could potentially lead to more buy-in, such as an Enterprise Business Impact Analysis (top-down BIA approach). Assigning roles = creating capability? I thought assigning recovery roles meant we were covered. Half of them didn’t know they were even assigned. Lesson: If you are creating plans for each department, then you have dozens or more recovery teams to keep track of. People leave, new people come in, and you have to keep track of and train them, just for it all to happen again. Even after you have done all that, they will do what leadership tells them to do in an event, not what they told you for their "plan." Exercises will drive change? I thought a solid tabletop would shift culture. People nodded, then returned to business as usual. Lesson: If nothing changes after the exercise, it was just a well-dressed fire drill at best. We tend to focus our tabletops on large issues that have a severe impact to the organization, but don't look at the day-to-day disruptions that we typically have to handle more often. In my previous role as a Crisis Manager, I spent the majority of my days dealing with applications going "down" or having latency issues more than I dealt with larger scale disruptions. Over the course of my time as that Crisis Manager, I had 4 larger scale events, 2 ice storms and 2 hurricanes. Documentation = readiness? I thought documentation meant we were prepared. But no one could find it, let alone use it, when it actually mattered. Lesson: Plans get left on the bookshelf. People react to each disruption differently than they planned for. Resilience doesn’t fail because of bad planning. It fails because we design programs around how we think people should behave , rather than how they actually do . So Why Say All This? Because I’m tired of watching real resilience take a backseat to performative “thought leadership," and I’m tired of watching the people doing the work get passed over for people capitalizing on someone else’s ideas. (If you haven’t checked it out yet, I highly recommend reading Scott Baldwin’s Unified Resilience Framework . He’s on to something with that.) I didn’t get into this field for likes, panels, or podcast downloads. I got into it because I think it’s an extremely important field—one that not only helps organizations, but also supports the people inside them. (And I’m pretty sure most of us feel the same way.) When things break—really break—leaders don’t need another pretty chart or LinkedIn tagline. They need the truth. They need muscle memory. They need someone who knows what doesn’t work—because they’ve lived it. What You Can Do Keep building. Let the copycats chase your tail. Call it out. Not for ego, for the survival of the field. Support the doers. Hire them. Refer them. Amplify them. Design for real behavior. Not ideal scenarios. Because when the lights go out, no one cares who had the best stage presence. They care who shows up, who steps in, and who gets them back on their feet. You can steal a framework. You can steal a blog post. You can even steal a slide deck. But you can’t fake competence. And you can’t fake resilience.
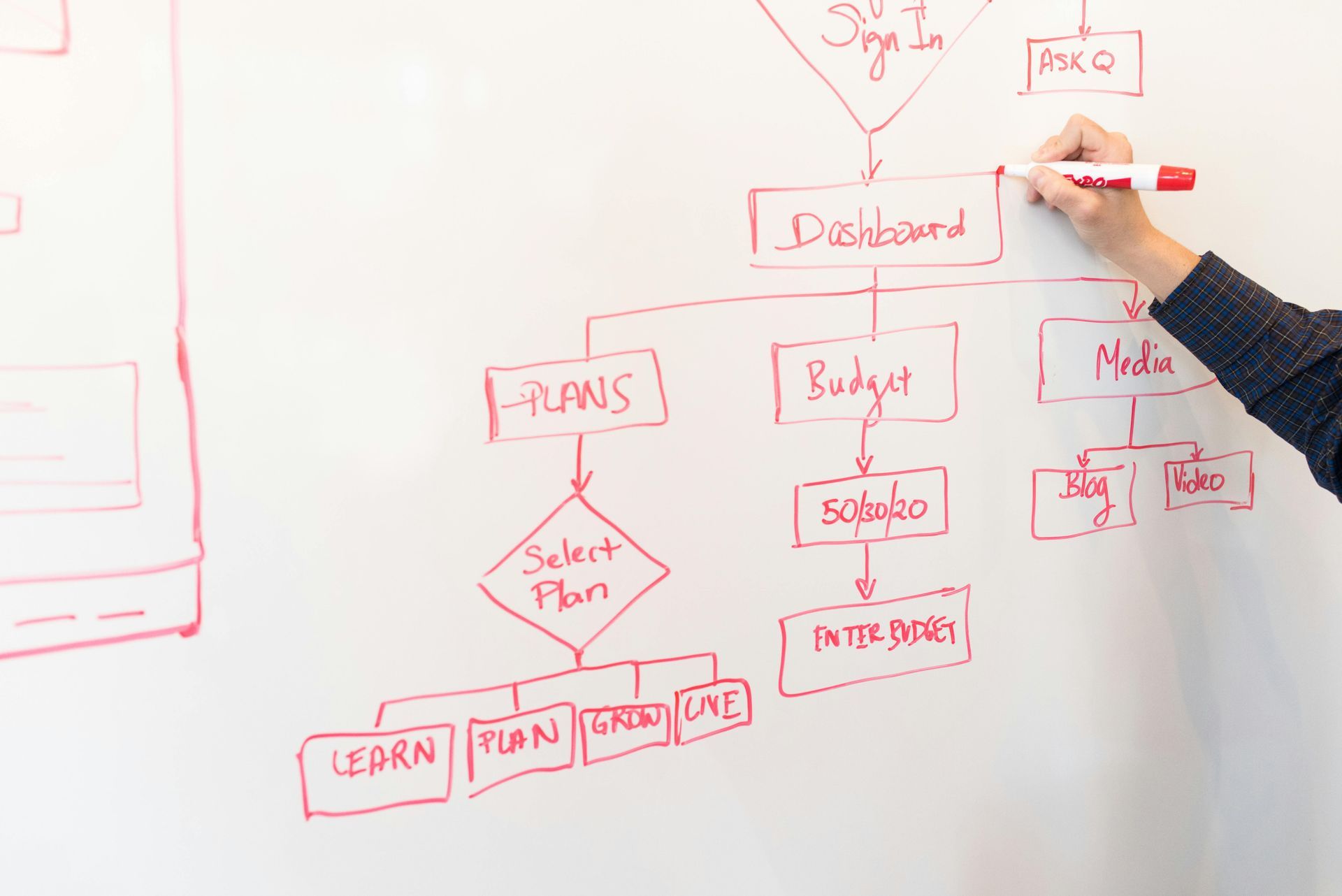
Let’s cut to it: Workflow dependency mapping looks useful — until you realize no one uses it when it matters. You can chart every input, every output, and every branch of every process. But when something breaks, people don’t follow the map. They ask: “What’s down?” “How long can we live without it?” “What has to stay running no matter what?” That’s why smart resilience programs are ditching spaghetti maps and asking a better question: “What’s the minimum acceptable availability for this service over the course of a year?” What Is Percentage Availability? It’s not a gut check. It’s not a vague SLA. It’s a clear, numeric threshold : “This service must be available 99% of the time annually.” “This process can only be down for ~88 hours a year (1%).” “This function only needs 80% availability to be considered successful.” This gives you a tangible, outcome-based requirement for continuity — not just a list of dependencies that might or might not matter in a disruption. Why Workflow Dependency Mapping Misses the Mark It’s Static Processes and systems change constantly. Maps don’t. It’s Not Prioritized Everything looks connected, but it doesn’t tell you what’s vital vs. what’s just annoying to lose. It Doesn’t Translate to Exec Decisions No executive makes decisions off a diagram. They need to know: “What are we failing to deliver, and how long can we fail before it matters?” It’s a Maintenance Burden Who’s updating all those dependencies quarterly? No one. Let’s be real. Why Percentage Availability Works Better Aligns With Business Objectives You’re not asking “What does this connect to?” You’re asking: “How much uptime does this service need to meet customer expectations, compliance, and revenue targets?” Drives Response Planning If something has to be up 99.9% of the year, you don’t just plan a recovery, you build failovers, redundancy, rapid response. It tells you where to spend your effort. Simplifies Risk Conversations Availability gaps are easy to quantify and defend. You can say, “We’re currently only designed for 90% availability, but leadership expects 99.5%. Here’s the delta. Here’s the cost to fix it.” Scales Without Getting Lost in the Weeds You don’t need to map 400 steps. You need to know how often the thing can go down before your customers, your regulators, or your board notice. Realistic Resilience Isn’t About Mapping Everything It’s about setting clear expectations: What must stay running? How often? How fast do we recover when it doesn’t? Percentage availability gives you that answer. Stop glorifying documentation and start defining performance. Your org doesn’t need another diagram. It needs a standard for continuity . Need help defining percentage availability targets that actually make sense? That’s what we do. No fluff. Just clarity.

Let’s get something straight: The resilience software market is long overdue for a reckoning. For years, enterprise platforms like Fusion Risk, RSA Archer, and BC in the Cloud (BCIC) have positioned themselves as the gold standard for business continuity and crisis management. They promise flexibility and maturity—yet, in my experience, they often deliver bloated architectures, outdated templates, and UIs that feel like they were designed before the smartphone existed. And the pricing? These platforms can easily charge six figures just to get started. Then come the “extras”: implementation fees, integration costs, training packages, ongoing support, and endless consulting hours. Before you know it, you’re sinking budget into a system your team barely uses. Built for Consultants, Not for Crises These systems weren’t literally built by PwC or Deloitte—but they may as well have been. In my opinion, their architecture reflects a consulting-first mindset: checkbox-heavy, audit-centric, and painfully rigid. They’re optimized for reviews, not real-world response. The result? Endless dropdowns. Disjointed modules. Workflows that make sense on a flowchart but collapse in a crisis. What Real Users Are Saying This isn’t marketing spin—these are direct quotes from real-world users: RSA Archer “Complex, not user friendly, and bulky. The interface just looks old… like opening an old Nintendo system from 1990.” “There are way too many screens. A new user can get lost and would need a lot of help.” Fusion Framework “Implementation is complex. Customizations require help from Fusion support every time.” “It’s powerful, but so bloated. Every time we want to do something simple, we end up stuck in configuration hell.” BC in the Cloud (BCIC) While once known for flexibility and price, BCIC’s newer version tells a different story: “To get the most from the tool, one really needs to have HTML/Java-type knowledge… If you don't, you have to rely on their support team.” “The plan-building feature is a little archaic, but it gets the job done.” “Advanced reporting capabilities are limited… need separate test environment—adds overhead.” In my view, the low-code flexibility that BCIC was once praised for is largely gone. What’s left is a system where simple tasks feel over-engineered, overly technical, and support-dependent. Not exactly the agile solution today’s resilience teams need. What People Actually Want From years in the trenches, I’ve seen that resilience teams consistently are looking for: Fast onboarding – not six-month implementation timelines Intuitive UI – no screen mazes, no friction Component-based solutions – not massive, inflexible suites Templates that match how the business actually operates or the ability to create their own templates Process-driven workflows – built for continuity, not just compliance Start with Design, Not with a Demo One of the biggest mistakes organizations make is buying software before they’ve defined what their program should be. Before you take a single demo, design your program. Build your templates. Outline your workflows. Know what you need. Too often, organizations reverse that process: contorting their strategy to fit whatever tool they just purchased. That’s how you end up with rigid plans, awkward workarounds, and low adoption. Every organization is different. Culture, structure, and decision-making vary widely—and your resilience program should reflect that. Tools should support your model, not impose theirs. Executives Quit Before Your Implementation Does Another hard truth: many resilience program sponsors may not survive long enough to see the tools they buy actually implemented. Multi-year implementations don’t just waste time, they burn political capital. One landmark study found that one in six large-scale IT projects becomes a “Black Swan,” overrunning costs by 200% and timelines by nearly 70% . When that happens, the executives who sponsored the project are often replaced before the tool ever delivers value. In our direct experience, we’ve seen this play out: A BC/CM director champions a new system. Implementation stalls. Leadership changes. The program loses momentum or worse, gets shelved entirely. Projects fail not just from bad tools, but from fatigue . Executive support erodes with every missed milestone. In many cases, if you're still configuring when your sponsors have mentally moved on, you’re running uphill. This is why the process must be practitioner-led and designed up front . You need clarity before you spend. Otherwise, you’ll be rebuilding under new leadership anyway. The Practitioner-Built Difference This is exactly why we’ve built tools differently. At PAI Consulting, we don’t build for certifications, audits, or shelfware. We build for functionality, speed, and survival. We’ve led real response teams. We’ve seen legacy platforms fail under pressure. And we’ve used that frustration to build better tools. Our suite includes: Scenario TTX – A smarter, AI-powered tabletop engine that generates dynamic injects, adapts to real-time decisions, and produces actionable after-action reports—cutting prep time while raising engagement. Business Resilience Navigator – A maturity assessment and roadmap tool that delivers strategic clarity. It moves beyond compliance checklists and helps organizations build a resilience program grounded in actual capabilities. Resilience Planner Studio (coming Q3 2025) – A modern, modular planning engine for continuity, risk, and crisis workflows. Studio is our take on the now-defunct (and missed) Sustainable Planner platform, giving teams full control to build, assign, and manage their own planning templates, assessments, and logic—without being boxed in by vendor limitations. Resilience Planner 360 (coming late 2025) – Our full-scale, response-ready platform built on our Realistic Resilience framework. Unlike rigid platforms built for auditors, 360 helps teams plan, test, and respond in real time. It supports BIAs, AIAs, playbooks, CMT role assessments, and incident tracking—all tied together by a framework that reflects how organizations actually operate during disruption. Each tool is practitioner-tested, modular, and designed for the way real resilience work gets done—fast, focused, and grounded in operational truth. The Market Is Shifting Organizations are waking up. They’re tired of: Paying top dollar for slow, bloated systems Letting software vendors and consulting partners dictate workflows Spending six months to over three years on implementation only to realize no one’s using the tool The next wave of resilience software will be practitioner-led. Lean. Responsive. Built to serve actual needs, not theoretical frameworks or RFP checklists. Ready for Something Better? We’re not just pointing out problems, we’re working to solve them. Resilience Planner Studio & Resilience Planner 360 are our answers to the overpriced, overbuilt legacy platforms that dominate the market. They are being built from the ground up by practitioners who understand a core truth that big vendors seem to ignore: Let’s be honest—these platforms are not used every day by most of your workforce. So why are you paying as if they are? In reality, the only regular users are your continuity, risk, and crisis teams. What they need isn’t bells and whistles—they need speed, clarity, and reliability. That’s why our planning tools will be: Fast to deploy and intuitive to use Modular and scalable—no “all-or-nothing” commitments Designed for planning, exercising, and response Built for actual users, not just the executive sponsor Most importantly: we’re not trying to drain your budget for a platform that collects dust between audits. We’re building tools that show up when they’re needed—and stay out of the way when they’re not.

Tabletop exercises are a cornerstone of any organization’s resilience program, bringing multiple stakeholders together to rehearse a hypothetical crisis, identify gaps, and refine processes before a real incident strikes. Yet, many teams still rely on handcrafted or semi-automated scenarios that quickly become repetitive, lack meaningful analytics, and require constant manual upkeep. Scenario TTX was built from the ground up to eliminate each of those limitations. By combining a curated set of scenario types/subtypes with an AI engine that (1) generates the narrative and injects on-the-fly, (2) adapts each inject based on live participant responses, and (3) provides instant, multi-dimensional scoring, Scenario TTX delivers dynamic, data-rich, and scalable tabletop exercises – every time. Below, we explore how Scenario TTX delivers far greater value than DIY or static alternatives (even those bolstered with generic AI prompts), highlighting features like true inject adaptivity, AI-driven evaluation, flexible exercise lengths, and built-in support for up to ten remote participants. 1. Adaptive Injects: Fresh Challenges Every Time 1.1 From Scenario Types/Subtypes to Tailored Playbooks Unlike a “static PDF library,” Scenario TTX lets you pick from scenario types (e.g., “Natural Threats,” “Cybersecurity,” “Reputational”) and then select a precise subtype (for instance, “Sustained Drought,” “Ransomware Attack”). At run-time, the AI engine builds the full scenario narrative , including background context, stakeholder roles, critical resources, and an initial inject, automatically. With a handcrafted or one-off AI-prompted scenario, every run ultimately feels nearly identical: participants anticipate the sequence of injects, and exercises lose their realism. Scenario TTX’s scenario-type + subtype approach guarantees a unique starting point each time you launch an exercise, ensuring even the first inject reflects the latest industry context, vendor lists, or organizational specifics that you’ve configured. 1.2 Inject Variations Based on Participant Responses The true power of Scenario TTX emerges once participants begin responding. Each answer is captured, analyzed, and used to generate the next inject in real time. For example: Proactive Communications Detected? If the team’s first response prioritizes stakeholder outreach, the AI might escalate to “Local regulatory body publicly questions financial stability,” testing whether they can pivot from outreach to regulatory engagement. Technical Focus Only? If IT immediately throws all resources at fixing systems without addressing client concerns, the AI could shift to “Major client threatens to withdraw funds unless formal recovery plan is presented,” forcing a new decision path. Because responses directly drive each subsequent inject, no two runs ever feel the same , even if you select the exact same scenario type/subtype days, weeks, or months apart. This continuous adaptivity uncovers fresh insights every time, whether you’re engaging the same group or rotating different teams through that scenario. 1.3 Remote, Multi-User Collaboration (Up to 10 Participants) Scenario TTX is built for modern, distributed teams. Up to ten participants can log in simultaneously, whether they’re in the same conference room or scattered across the globe. Each participant submits an independent response to every inject. The facilitator then has complete control over how to proceed: Use All Responses: Ideal for large-team consensus – present the aggregate sentiment, drive a discussion, and move forward based on the majority. Select Some Responses: Choose the most relevant answers from a subset of participants (e.g., senior leadership) to guide the next inject. Use a Single Response or None: If one expert’s viewpoint is critical (say, your Chief Risk Officer’s input), the facilitator can advance using just that response or override all answers to simulate a “rogue inject” from a threat actor. This flexibility makes it possible to run truly collaborative, multi-perspective exercises without anyone physically present. Compared to a DIY PDF (where remote participants must email their notes back to a single facilitator), Scenario TTX’s built-in collaboration saves time, reduces miscommunication, and keeps the exercise flowing naturally. 2. AI-Driven Evaluation: Rapid, Data-Rich Debriefs 2.1 Automated Scoring Across Four Key Dimensions When the exercise concludes, whether it’s a 1-inject micro-simulation or a 20-inject deep dive, Scenario TTX instantly produces a comprehensive After Action Report. On the dashboard, the user can select any of their completed tabletops to generate an AI-produced Scorecard that includes: Overall Exercise Rating: A star-based aggregate score (for example, 2 out of 5 stars) accompanied by a clear “Needs Improvement” or “Adequate” flag. Summary Assessment: A concise paragraph highlighting both strengths (e.g., “Team proactively recognized regulatory obligations”) and areas for improvement (e.g., “Delayed decision-making slowed response”) based on actual responses. The assessment scorecard includes: Scenario Outcome Rating: A judgment on whether the team “Contained with Gaps,” “Escalated,” or “Achieved Full Control,” paired with an AI-generated justification that cites specific responses. Team Behavior Breakdown: Individual scores (1–5 stars) for each dimension— Communication , Decision Making , Role Execution , and Flexibility —plus bullet-pointed Strengths and Areas for Improvement for each dimension. For instance: Communication (3/5): Strength: “Participants drafted an on-brand FAQ document.” Improvement: “Needed earlier sharing of situational updates to all stakeholders.” Decision Making (2/5): Strength: “Formed a dedicated task force within 10 minutes.” Improvement: “Took too long to escalate vendor negotiations.” Industry Benchmarking: A percentile ranking (e.g., “55th percentile in Financial Industry”) comparing your team’s performance to hundreds of peers who ran the same scenario type/subtype in the last 12 months. All of this is assembled within minutes , with no manual note-taking or biased interpretation. Even if you attempted to “DIY” that analysis in a spreadsheet or through a standalone AI tool, you’d struggle to replicate the depth and objectivity of Scenario TTX’s built-in model. 2.2 Consistent, Objective Feedback Over Time Human facilitators can inadvertently focus on the loudest voices or specific injects that resonate with them, skewing post-exercise feedback. Scenario TTX applies the same AI-driven rubric to every exercise, regardless of who’s in the room. Over time, you build an unbiased data history showing performances across multiple exercises. That consistency is invaluable when you want to: Track progress (e.g., “Finance’s Decision Making improved from 2.2 to 3.8 over four quarter-end drills”) Identify recurring gaps (e.g., “Branch Managers consistently underperform in Flexibility during sudden reputational injects”) Justify training budgets with hard data rather than anecdotes Trying to replicate that level of consistency manually, through patchy spreadsheets or ad-hoc notes, is both time-consuming and prone to blind spots. Scenario TTX’s automated evaluation ensures you always have a clear line of sight into your organization’s evolving strengths and weaknesses. 3. Unlimited Exercises & Flexible Lengths 3.1 Spin Up New Runs—No Rework Required With a DIY or handbook approach, every new run means manually updating Word documents, rewriting inject lists, and re-verifying that scenario details (vendor names, system configurations, contact information) remain current. Scenario TTX removes that overhead entirely. Once you enter just your organization name, industry, number of employees, and locations , the AI takes care of: Researching Your Company Context: Leveraging publicly available data and industry norms so injects align with your actual risk profile. Maintaining Up-to-Date Details: As the AI’s underlying dataset updates (new threat intelligence, evolving industry best practices), future runs automatically reflect those changes without any user action. From there, you can launch unlimited tabletop exercises with a few clicks – no reprinting PDFs or reworking inject lists for each new exercise. 3.2 Choose the Right Length for the Right Audience Scenario TTX’s flexible architecture lets you run: 1-Inject Micro-Simulations: A 10-minute “pulse check” —for instance, “Your primary cloud provider announces a major data breach. Outline your first course of action.” Within minutes, you receive a snapshot evaluation on Communication and Decision-Making. 5-Inject Focused Drills: A 30-minute department-level exercise —e.g., HR and Legal test a “Vendor Data Breach” scenario with injects that adapt to the team’s actual actions (employee notifications, regulatory reporting, media statements). 20-Inject Deep-Dive Tabletop: A multi-hour enterprise stress test that can be paused after any inject. Because Scenario TTX auto-scores each inject, you can pause at inject 7, reconvene days later, and pick up at inject 8 without having to rebuild or reconfigure anything. In a DIY environment where you cobble together inject lists or prompt an AI chatbot to “generate 20 injects” you must manually anticipate and sequence every inject, then keep track of which version each group is using. Scenario TTX centralizes that entire process, so you focus on learning outcomes instead of document prep. 4. Why Standalone AI or Handcrafted Scenarios Fall Short It’s true that free or open-source AI tools can help you brainstorm realistic injects. You might prompt ChatGPT (or a similar model) with: “Generate five injects for a drought scenario affecting a community bank’s loan portfolio.” You can coax a plausible text sequence. But attempting to replicate Scenario TTX’s integrated workflow creates four key challenges: Real-Time Adaptivity: A generic AI chatbot can’t “listen” to your team’s answers, pivot mid-exercise, and craft the next inject accordingly. Instead, you’d need to pause, copy the team’s responses, re-prompt the AI, manually insert a new inject, and resume, destroying immersion and adding latency. Scenario TTX’s AI engine does that pivot automatically, in real time. Automated Scoring & Analytics: To score Communication, Decision Making, Role Execution, and Flexibility across multiple injects, you’d need to define a custom rubric, capture every answer in separate documents, then manually quantify and summarize performance. That process is both time-consuming and subjective. Scenario TTX’s AI provides an instant, objective, multi-dimensional scorecard complete with narrative strengths and gaps. Industry Benchmarking: Free AI tools offer no built-in dataset to compare your results against peers. You’d have to collect data from dozens of other organizations, normalize it to a common scale, and build your own benchmark tables. Scenario TTX already maintains an ever-growing database of exercises letting you see where you rank among “Banking & Finance” teams running the same “Drought” scenario, for instance. Scaling to Multiple Teams & Remote Participants: Every time you want to run an exercise, you must repeat steps 1–3 manually and potentially rework inject sequences to keep them “fresh.” Additionally, facilitating remote, multi-user collaboration via email, video calls, or chat tools can be clunky, answers get lost in threads, and the facilitator must compile them manually. Scenario TTX’s built-in support for up to ten remote participants solves both issues: you scale effortlessly, and every remote user’s independent response feeds seamlessly into the adaptive inject logic. In short, while standalone AI can help you generate content, it cannot match Scenario TTX’s fully integrated approach: adaptive scenario generation, automated multi-dimensional scoring, real-time remote participation, and effortless scaling across multiple teams. 5. Key Benefits of Scenario TTX vs. DIY Approaches

Introduction: The Broken Promises of Business Continuity The resilience industry has a trust problem. Not because systems fail, that’s inevitable, but because the response to failure is wrapped in red tape, vanity metrics, and meaningless jargon. Clients/customers don’t need perfection; they want honesty, clarity, and a sense that someone is in control. Yet traditional business continuity planning clings to outdated concepts like RTOs and boilerplate SLAs while ignoring what really matters: how people feel when things go wrong. At PAI Consulting, we call this out for what it is: resilience theater . That’s why we’ve built our Realistic Resilience methodology around the truth: systems fail, third parties falter, and clients/customers will forgive you, as long as you treat them like adults. Why RTOs Are Vanity Metrics The Recovery Time Objective (RTO) is one of the most widely used (and widely misunderstood) metrics in resilience planning. It represents the maximum amount of time a system or function can be down before significant impact occurs. But in practice? RTOs are often guessed, not calculated. They're set without real input from IT or third parties. They are rarely accurately or realistically tested or validated. And worst of all, they are virtually never communicated to clients/customers. This leads to absurd situations: a service outage occurs, and even if you're technically "within your RTO," clients/customers are furious because they had no idea what that meant. Or worse, they weaponize the RTO as a hard expectation, regardless of the root cause. Instead of relying on fictional timelines, we advocate for percentage-based availability and transparency-driven communication. SLAs: The Illusion of Control Service Level Agreements (SLAs) often promise 99.9% uptime, 24/7 support, and rapid response. But what they really offer is legal cover. Vendors treat SLAs as compliance documents, not living operational commitments. We’ve seen organizations get burned because their vendor hit the letter of the SLA while completely violating the spirit of trust and service. Even a 99.999% uptime guarantee still allows for ~5 minutes of downtime per month, but those minutes can matter if they occur during a critical transaction. And critically, SLAs typically do not differentiate the nature of the outage : A full system crash counts the same as a degraded system with latency issues. A partial availability problem, where some users are affected but not all, may not even register as an SLA violation. Intermittent errors, performance slowdowns, or localized failures are often invisible in standard SLA reports. This misalignment creates a dangerous blind spot. From the customer’s perspective, any degradation in performance feels like a failure . But under the SLA? Everything looks fine. Instead of worshipping at the altar of five nines, Realistic Resilience encourages organizations to: Track actual availability month over month Share real mean time to recovery (MTTR) stats Be proactive in customer comms when things break Acknowledge and address partial, latent, or non-total outages as real customer-impacting incidents Third-Party Risk: More Than Questionnaires Current third-party risk frameworks obsess over vendor questionnaires, due diligence checklists, and static scorecards. But when things go wrong, all that prep means nothing if there's no plan to communicate. Worse, many organizations treat third parties as magical black boxes: “They’ll handle it.” No. You’re accountable to your clients/customers even for things you don’t directly control. Realistic Resilience flips the script by embedding crisis communication and accountability into third-party relationships: We assume vendors will fail at some point. We require communications protocols , not just SLAs. We treat third-party disruptions as brand risks, not just ops risks. Crisis Management Isn't Just for Disasters One of the most dangerous misconceptions is that crisis management is only activated when there's a disaster, such as a cyberattack, natural catastrophe, or full-blown outage. But in the modern resilience environment, a 10-minute login issue at your SaaS provider could do more reputational damage than a day-long power outage. Realistic Resilience advocates for micro-activation of crisis comms : Any issue that affects customer experience = activate the plan. Fast, plain-language updates trump silence and delay. Train teams to respond to perception, not just impact. The difference between a crisis and an inconvenience is how you handle it. What Clients/Customers Really Want: Trust, Not Perfection Clients/customers are surprisingly forgiving, IF you're transparent. Tell them what's happening. Tell them what you're doing. Tell them when they’ll hear from you again. They don’t care about your RTO. They care that you show up. Realistic Resilience embraces this by aligning metrics with customer experience: Use uptime percentages , not recovery guesses Share real incident timelines , not idealized plans Replace "blame the vendor" responses with co-owned resolution strategies Case Study: A Realistic Resilience Response in Action A regional bank relying on a third-party SaaS provider experienced a partial service outage during peak hours. The vendor’s SLA technically allowed for up to 30 minutes of monthly downtime, and the system was restored in 22 minutes. But by the time the platform was live again, dozens of high-value clients had already submitted complaints. Using the Realistic Resilience framework, the bank’s crisis team activated their communications protocol within the first 5 minutes after confirming the outage: A banner message was posted to the login screen acknowledging the issue. Clients were emailed within 15 minutes with a clear, jargon-free explanation. A follow-up message provided recovery confirmation and a brief postmortem within 2 hours. Even though the SLA wasn’t violated, the team treated the event as a trust risk, not just a technical one. The result? Near-zero client churn and several clients/customers responded with praise for the transparency. Conclusion: Let’s Kill the Theater If resilience planning continues to rely on fake deadlines, obscure metrics, and silence during actual disruptions, it will continue to fail. RTOs should not be front-line commitments. SLAs should not be escape hatches. Third-party risk should not be checkbox compliance. At PAI Consulting, we don’t chase illusions. Realistic Resilience means planning for the messy, unpredictable, and very human reality of modern service delivery. And it means treating your clients/customers like people, not SLAs. Because in the end, resilience isn’t about uptime, it’s about trust recovery.

In the world of business continuity and operational resilience, certifications from DRI and BCI have long been seen as the standard. You take a course, pass an exam, and suddenly you’re a “certified” continuity professional. But for those of us who’ve actually worked through real disruptions, those credentials often fall flat. They focus on documentation, theory, and checklists - yet skip over the messy, unpredictable reality of actual crisis response. And here's the real problem: They’re failing the next generation of resilience professionals. The Current Certification Model Is Broken The goal of certification should be to build capability, not just credibility. It should prepare someone to walk into a chaotic situation, lead a team under pressure, and make time-critical decisions with incomplete information. But instead, we’re training newcomers to: Fill out outdated BIA templates Memorize lifecycle terminology Recite definitions for risks they’ve never seen in action We’re not equipping them, we’re encasing them in legacy thinking. Documentation Isn’t Leadership You can be certified without ever: Leading a response Running a live exercise Talking to executives in a crisis Making a time-critical recovery decision And that’s the gap. We’re credentialing people to write plans, not to lead responses. The Pay-to-Play Problem Honestly, these programs are designed to sustain themselves. You pay for training, pay for the test, and pay annual fees to keep your letters. But none of that guarantees you can actually do the job when it counts. For someone new to the field, it’s an expensive entry point that offers surprisingly little return unless they're propped up by real-world mentorship. I can remember a time when an employee of mine with 0 years of experience received a CBCP - right then, I knew the certification wasn't worth it. What Certification Should Actually Do If we care about building a stronger field, we need to rethink the model from the ground up, not just to validate the experts, but to train the next wave of professionals to be effective, adaptable leaders and here's what that could like like: 1. Real-World Scenario Testing - Don’t just pass a quiz. Respond to complex, evolving crisis scenarios—just like you’ll face in the real world. You don’t learn to lead from a workbook. 2. Portfolio-Based Certification - Bring proof. Show your actual work: plans, exercises, incident responses, risk analyses. Certify based on what you’ve done, not what you’ve heard in a class. 3. Mentored Pathways - Pair new professionals with real-world resilience leaders. Make experience part of the curriculum, not something they’re left to figure out on the job. 4. Cross-Skill Development - Train people across disciplines: cybersecurity, communications, executive briefings, time-based recovery, vendor risk. No more single-silo certs. 5. Focus on Response, Not Just Readiness - The best plan won’t save you if no one knows how to act on it. Certification should be about leading the response, not just writing the prep work. It's Time for More Than Letters DRI and BCI have long lived past their usefulness. We’re in a different era now. Threats are faster, systems are more complex, and leadership expectations are higher than ever - and yet, they are still teaching the same thing from decades ago. It’s time for a certification model that actually builds: Real capability Adaptive thinking Practical leadership Cross-functional resilience Let’s stop handing out gold stars for downloading templates and start training the kind of leaders this field actually needs.
